

2026 年,AI 推理算力已成为稀缺资源。由于需求爆发式增长以及养龙虾热潮,主流 API 服务商面临前所未有的压力,降智、限流、涨价已成常态。本视频解析 2026 年性能模型 Qwen 3.5 9B ,教你如何利用 llama.cpp 在消费级电脑上部署ai模型,实现安全、稳定、经济的生产级 AI 性能。
01. 序言:AI 基础设施的“主权时代”
范式转移: 2025-2026 年,AI 正在从“中心化云端”走向“本地边缘化”。
为什么要本地化?
数据主权: 物理隔离,拒绝提示词被泄露。
经济性: 日均 10 万 Token 调用量,3-6 个月即可回本。
02. 工具链选型:谁才是 2026 的推理之王?
结论:
llama.cpp是基石。它支持 CPU/GPU 混合推理,且 GGUF 格式在显存分配上具有无可比拟的精确度。
03. 深度解析:Qwen 3.5 9B 架构突破、高性价比
阿里 Qwen 团队在 2026 年推出的 9B 版本,是目前小型模型的巅峰:
混合注意力机制: 采用 Gated DeltaNet。
线性增长: 32 层网络中,Gated DeltaNet 与 Full Attention 以 3:1 交替。
长文本支持: 原生支持 26.2 万 Token,YaRN 技术可扩展至百万级。
📊 显存占用分析(Qwen 3.5 9B)
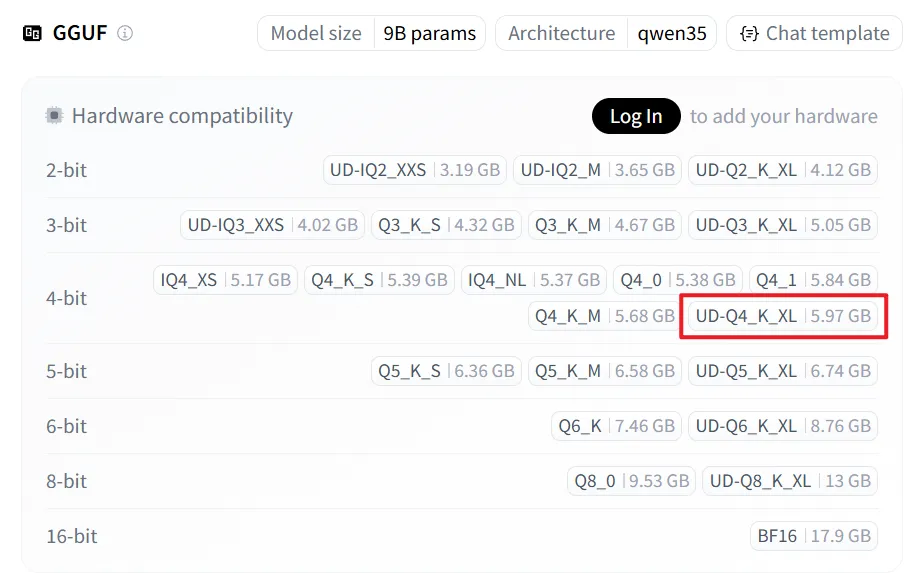
Q4 量化是“甜点位”——仅损失 3% 逻辑能力,换取 3 倍显存节省。
04. 实战演示:四步完成全链路部署
第一步:基础设施环境
消费级电脑配置
系统: Windows 10 IoT Enterprise LTSC 2021 21H2 64位
处理器: 12th Gen Intel(R) Core(TM) i3-12100F 四核
主板: MAXSUN MS-TZZ H610M ( 英特尔 H610 芯片组 )
内存: 32GB DDR4 2400MHz ( 16GB + 16GB )
显卡: NVIDIA GeForce RTX 3050 ( 8GB / 英伟达 )
驱动:安装 NVIDIA Studio Driver最新驱动
第二步:获取 llama.cpp和cudart
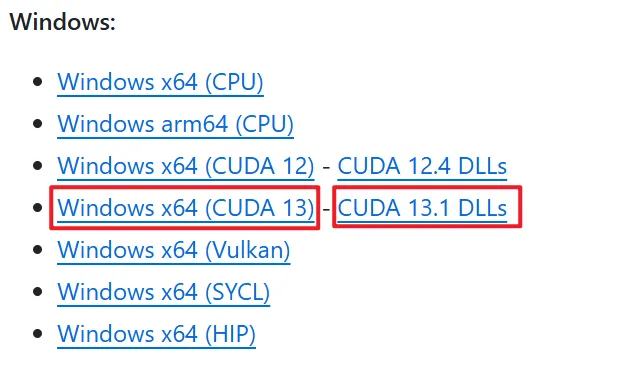
前往 GitHub 下载 https://github.com/ggml-org/llama.cpp
llama-b8461-bin-win-cuda-13.1-x64.zipcudart-llama-bin-win-cuda-13.1-x64.zip
第三步:模型下载(Hugging Face CLI)
国内推荐镜像站下载:https://hf-mirror.com/
unsloth/Qwen3.5-9B-GGUF:https://hf-mirror.com/unsloth/Qwen3.5-9B-GGUF
量化的模型+模板,两个文件
第四步:启动 OpenAI 兼容 API 服务
.\llama-server.exe `
--model Qwen3.5-9B-UD-Q4_K_XL.gguf ` # 本地模型文件路径及名称
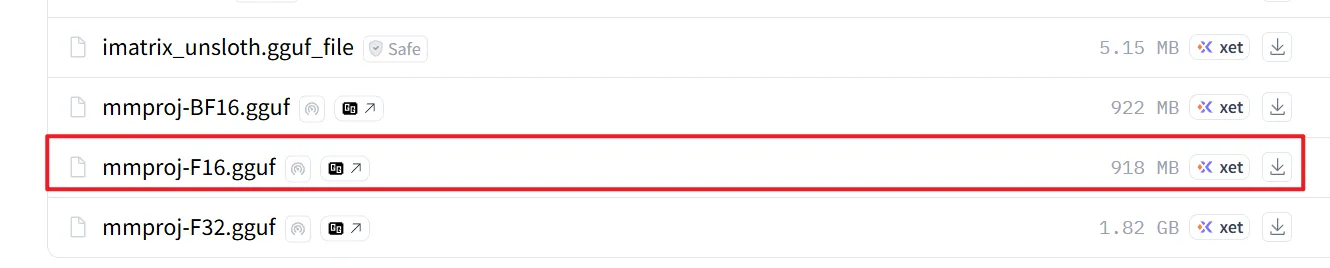
--mmproj mmproj-F16-9B.gguf ` # 多模态视觉投影文件,让Qwen能“看图”
--alias "unsloth/Qwen3.5-9B-GGUF" ` # 客户端api链接模型时,显示的名称
--ctx-size 65536 ` # 设置64k上下文,让它能读更长的文档,太大容易爆显存,推荐32k
--temp 0.7 ` # 创造力调节器,参照官方调整即可
--top-p 0.8 `
--top-k 20 `
--min-p 0.00 `
--port 8080 ` # 暴露服务端口,自定义
--n-gpu-layers 99 ` # 将99层模型层(本模型大概40层)全部“塞进”显存加速,保证全显存运行
--flash-attn auto ` # 能自动用更少的显存算更长的文本(必开)
--reasoning off ` # 关闭思考(可选)
--cache-type-k q4_0 ` # 开启缓存量化
--cache-type-v q4_0 ` # 开启缓存量化
--batch-size 4096 ` # 增加吞吐量,默认 2048
--ubatch-size 1024 # 增加吞吐量,默认 512本地部署不再是极客的玩具,而是 2026 年企业和开发者的核心资产。随着 Agentic AI(智能体)、龙虾的爆发,能够掌控本地算力的人,才拥有真正的 AI 自由。